課題1 AIの基礎理解
第3章 深層学習(ディープラーニング)
機械学習の発展をさらに大きく前進させたのが、「深層学習(ディープラーニング)」です。深層学習とは、人間の脳の働きを模した「ニューラルネットワーク」という仕組みを多層的に組み合わせ、大量のデータから複雑なパターンを自動的に学習する技術です。これによりAIは、従来の手法では困難だった画像認識、音声認識、自然言語処理といった高度な認識・理解を実現できるようになりました。
もともと機械学習は、データの中に含まれる特徴(特徴量)を人間が設計し、それをAIに学ばせるものでした。たとえば画像を認識させる場合、「エッジの数」「明暗の差」「形の対称性」など、人間が「これが重要だろう」と考える指標をあらかじめ設定し、それをもとにAIが分類を行っていました。しかしこの方法では、人間が特徴を誤って選んだり、複雑なデータ構造を見逃したりすることがありました。データが膨大で多様になるほど、人間が手作業で最適な特徴を設計するのは不可能になっていったのです。
この問題を解決したのが深層学習です。深層学習では、AIが「特徴量の抽出」までも自分で学ぶことができます。つまり、人間が「何を重視すべきか」を教えなくても、AI自身が大量のデータの中から本質的なパターンを発見するのです。この能力によって、AIは人間の感覚的な判断に近い柔軟さを持つようになりました。画像を見て「これは猫だ」と判断したり、音声を聞いて「これは“ありがとう”と言っている」と理解したりできるのは、この自動特徴抽出の力によるものです。
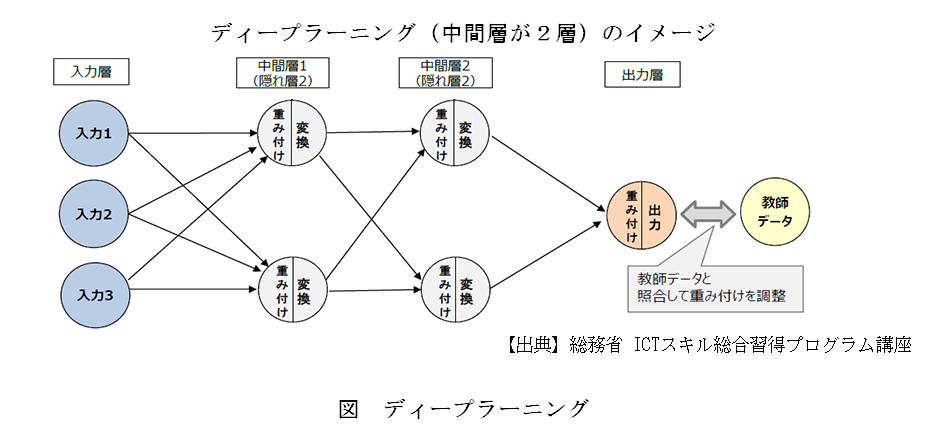
深層学習の中心にあるのが「多層ニューラルネットワーク」です。ニューラルネットワークは、人間の脳にある神経細胞(ニューロン)を数学的にモデル化したもので、入力層・中間層(隠れ層)・出力層の構造を持ちます。中間層を増やしていくことで、より複雑な関係を表現できるようになり、これを「深層(ディープ)」と呼びます。たとえば、画像認識では、最初の層が線や点を捉え、次の層が目や耳のような形を捉え、さらに上の層が「顔全体」という概念を理解する、といった階層的な学習が行われます。こうしてAIは、単なるデータの集合を「意味のある構造」として理解できるようになるのです。
このような深層構造を可能にしたのは、計算資源の飛躍的な進歩と、大量のデータ(ビッグデータ)の利用があったからです。2000年代後半からGPU(画像処理装置)を使った並列計算が一般化し、膨大なパラメータを短時間で更新できるようになりました。また、インターネット上に蓄積された画像・音声・テキストなどのデータが、AIにとっての「教材」として利用できるようになりました。こうした技術基盤の成熟が、深層学習の実用化を一気に後押ししたのです。
深層学習の登場によって、AIの応用範囲は飛躍的に広がりました。たとえばスマートフォンの顔認識や音声アシスタント、自動翻訳サービス、医療画像診断、さらには自動運転など、私たちの身の回りで使われている多くの技術がディープラーニングを基盤にしています。これらの分野では、人間の感覚に近いレベルでの認識・判断が求められるため、従来の機械学習では不十分でした。しかし深層学習は、多層構造によって抽象的な特徴を段階的に捉えることができるため、極めて高い精度を発揮するのです。
さらに深層学習は、現在の生成AIにも直結しています。ChatGPTなどの大規模言語モデルや、Stable Diffusionといった画像生成モデルも、すべて深層学習の延長線上にあります。これらのモデルでは、数百億から数兆に及ぶパラメータを持つ巨大なニューラルネットワークが、膨大なデータをもとに学習を行い、文章や画像を新たに生成します。つまり、生成AIは「深層学習の究極的な応用形態」といえるのです。
一方で、深層学習には課題もあります。モデルが巨大化するにつれて学習に膨大な計算コストと電力を要し、また学習過程がブラックボックス化することで「なぜその判断をしたのか」が分かりにくくなります。さらに、大量の学習データに依存するため、データの偏りや著作権の問題も指摘されています。したがって今後は、深層学習の高い表現力を活かしつつ、効率性や説明可能性を高める方向での研究が重要になっています。
このように、深層学習はAIの中核技術として、現代のAI革命を支える柱となっています。ルールに基づいて動くAIから、データを通じて世界を自ら理解し、表現できるAIへ。深層学習の誕生は、まさにその転換点であり、AIが「知る」から「理解する」、そして「創造する」段階へと進むための橋渡しとなっているのです。
もともと機械学習は、データの中に含まれる特徴(特徴量)を人間が設計し、それをAIに学ばせるものでした。たとえば画像を認識させる場合、「エッジの数」「明暗の差」「形の対称性」など、人間が「これが重要だろう」と考える指標をあらかじめ設定し、それをもとにAIが分類を行っていました。しかしこの方法では、人間が特徴を誤って選んだり、複雑なデータ構造を見逃したりすることがありました。データが膨大で多様になるほど、人間が手作業で最適な特徴を設計するのは不可能になっていったのです。
この問題を解決したのが深層学習です。深層学習では、AIが「特徴量の抽出」までも自分で学ぶことができます。つまり、人間が「何を重視すべきか」を教えなくても、AI自身が大量のデータの中から本質的なパターンを発見するのです。この能力によって、AIは人間の感覚的な判断に近い柔軟さを持つようになりました。画像を見て「これは猫だ」と判断したり、音声を聞いて「これは“ありがとう”と言っている」と理解したりできるのは、この自動特徴抽出の力によるものです。
深層学習の中心にあるのが「多層ニューラルネットワーク」です。ニューラルネットワークは、人間の脳にある神経細胞(ニューロン)を数学的にモデル化したもので、入力層・中間層(隠れ層)・出力層の構造を持ちます。中間層を増やしていくことで、より複雑な関係を表現できるようになり、これを「深層(ディープ)」と呼びます。たとえば、画像認識では、最初の層が線や点を捉え、次の層が目や耳のような形を捉え、さらに上の層が「顔全体」という概念を理解する、といった階層的な学習が行われます。こうしてAIは、単なるデータの集合を「意味のある構造」として理解できるようになるのです。
このような深層構造を可能にしたのは、計算資源の飛躍的な進歩と、大量のデータ(ビッグデータ)の利用があったからです。2000年代後半からGPU(画像処理装置)を使った並列計算が一般化し、膨大なパラメータを短時間で更新できるようになりました。また、インターネット上に蓄積された画像・音声・テキストなどのデータが、AIにとっての「教材」として利用できるようになりました。こうした技術基盤の成熟が、深層学習の実用化を一気に後押ししたのです。
深層学習の登場によって、AIの応用範囲は飛躍的に広がりました。たとえばスマートフォンの顔認識や音声アシスタント、自動翻訳サービス、医療画像診断、さらには自動運転など、私たちの身の回りで使われている多くの技術がディープラーニングを基盤にしています。これらの分野では、人間の感覚に近いレベルでの認識・判断が求められるため、従来の機械学習では不十分でした。しかし深層学習は、多層構造によって抽象的な特徴を段階的に捉えることができるため、極めて高い精度を発揮するのです。
さらに深層学習は、現在の生成AIにも直結しています。ChatGPTなどの大規模言語モデルや、Stable Diffusionといった画像生成モデルも、すべて深層学習の延長線上にあります。これらのモデルでは、数百億から数兆に及ぶパラメータを持つ巨大なニューラルネットワークが、膨大なデータをもとに学習を行い、文章や画像を新たに生成します。つまり、生成AIは「深層学習の究極的な応用形態」といえるのです。
一方で、深層学習には課題もあります。モデルが巨大化するにつれて学習に膨大な計算コストと電力を要し、また学習過程がブラックボックス化することで「なぜその判断をしたのか」が分かりにくくなります。さらに、大量の学習データに依存するため、データの偏りや著作権の問題も指摘されています。したがって今後は、深層学習の高い表現力を活かしつつ、効率性や説明可能性を高める方向での研究が重要になっています。
このように、深層学習はAIの中核技術として、現代のAI革命を支える柱となっています。ルールに基づいて動くAIから、データを通じて世界を自ら理解し、表現できるAIへ。深層学習の誕生は、まさにその転換点であり、AIが「知る」から「理解する」、そして「創造する」段階へと進むための橋渡しとなっているのです。